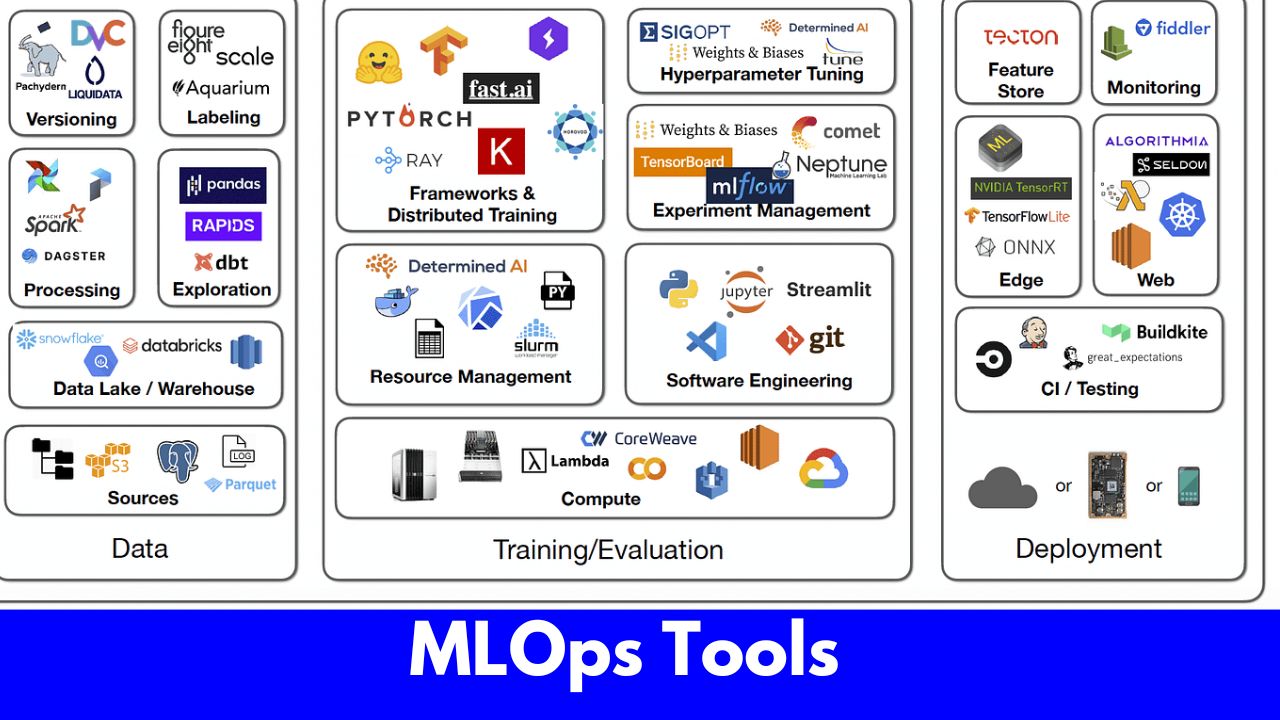
MLOps Tools #
MLOps (Machine Learning Operations) is a set of practices and tools designed to streamline and automate the deployment, monitoring, and management of machine learning models in production environments. It combines principles from both DevOps (Development Operations) and machine learning to ensure that ML models are deployed efficiently, managed effectively, and maintained reliably throughout their lifecycle.
MLOps ensures:
- Efficiency: Automates repetitive tasks, reducing manual effort and speeding up model deployment.
- Consistency: Ensures consistent and reliable model performance through standardized processes.
- Scalability: Facilitates scaling of models and infrastructure to handle increased workloads.
- Reliability: Enhances the reliability of ML systems by monitoring performance and quickly addressing issues.
- Compliance: Helps meet regulatory and compliance requirements by managing data security and model governance
MLOps Activities #
MLOps (Machine Learning Operations) encompasses a wide range of activities that are essential for developing, deploying, and maintaining machine learning models in production. Below is a comprehensive list of activities involved in MLOps:
1. Experiment Tracking #
- Logging and tracking experiments, including datasets, parameters, models, and metrics.
- Comparing different runs to identify the best-performing models.
- Tools: Weights & Biases, MLFlow, Comet ML, TensorBoard.
2. Data Versioning #
- Versioning datasets to keep track of changes over time.
- Ensuring reproducibility of experiments by linking models to specific versions of the data.
- Tools: DVC (Data Version Control), Pachyderm, Quilt.
3. Model Versioning #
- Versioning models to keep track of different iterations and updates.
- Managing multiple models in production with different versions.
- Tools: MLFlow, Git, DVC.
4. Hyperparameter Optimization #
- Automating the process of tuning hyperparameters to find the best configuration.
- Running distributed hyperparameter searches across multiple experiments.
- Tools: Optuna, Hyperopt, Ray Tune, Keras Tuner.
5. Model Training and Validation #
- Automating and managing the training of models at scale.
- Ensuring consistent validation processes and robust evaluation metrics.
- Tools: Kubeflow, SageMaker, Azure ML.
6. Model Packaging #
- Packaging models with their dependencies for deployment.
- Creating Docker containers or other environments to ensure consistent execution.
- Tools: Docker, BentoML, ONNX.
7. Model Deployment #
- Deploying models to various environments like cloud, edge, or on-premise.
- Managing APIs, load balancing, and scaling for serving models in production.
- Tools: TensorFlow Serving, TorchServe, KFServing, AWS SageMaker.
8. Monitoring and Logging #
- Monitoring model performance in production, including drift detection and anomaly detection.
- Logging predictions, errors, and performance metrics.
- Tools: Prometheus, Grafana, Seldon Core, Neptune AI.
9. Model Management and Governance #
- Managing access controls, auditing, and compliance for models.
- Ensuring models meet regulatory and ethical standards.
- Tools: MLFlow, ModelDB.
10. CI/CD for ML #
- Implementing Continuous Integration and Continuous Deployment pipelines specifically for machine learning workflows.
- Automating the retraining and redeployment of models based on new data or model improvements.
- Tools: Jenkins, GitLab CI, CircleCI, GitHub Actions.
11. Feature Engineering and Management #
- Automating feature extraction, transformation, and selection.
- Managing and versioning feature pipelines and stores.
- Tools: Feast, Tecton.
12. Data Pipelines #
- Building and maintaining data pipelines for ingesting, cleaning, and preparing data for models.
- Orchestrating complex workflows for data processing.
- Tools: Apache Airflow, Prefect, Luigi, Dagster.
13. Model Explainability #
- Providing insights into how models make predictions.
- Using tools and techniques to interpret and explain model decisions.
- Tools: SHAP, LIME, InterpretML.
14. A/B Testing #
- Running experiments to compare the performance of different models or versions in production.
- Collecting metrics to determine the best model for deployment.
- Tools: Google Optimize, Optimizely.
15. Drift Detection and Model Retraining #
- Detecting when a model’s performance degrades due to changes in data distribution.
- Automating the retraining process to update models based on new data.
- Tools: Evidently AI, WhyLabs.
16. Security and Compliance #
- Implementing security measures for model access, data privacy, and regulatory compliance.
- Ensuring secure data handling and model execution.
- Tools: Vault, Keycloak.
17. Collaboration and Documentation #
- Facilitating collaboration between data scientists, engineers, and other stakeholders.
- Documenting experiments, models, and processes to ensure transparency and reproducibility.
- Tools: Confluence, Notion, Git.
These activities collectively help in managing the lifecycle of machine learning models, ensuring that they are robust, scalable, and maintainable in production environments.
Some Popular MLOps Tools #
There are several MLOps tools that help manage machine learning workflows, experiment tracking, and model deployment. Here are some of them:
1. Neptune.ai #
- Features: Neptune focuses on experiment tracking, model registry, and metadata management. It integrates well with popular ML frameworks and supports collaboration across teams.
- Use Cases: Experiment tracking, hyperparameter optimization, model versioning.
2. DVC (Data Version Control) #
- Features: DVC is a version control system for machine learning projects that helps with data versioning, pipeline management, and experiment tracking. It works well with Git.
- Use Cases: Data versioning, reproducibility, pipeline orchestration.
3. KubeFlow #
- Features: KubeFlow is a Kubernetes-based platform that provides a suite of tools to deploy, scale, and manage ML models on Kubernetes. It includes components for training, serving, and monitoring models.
- Use Cases: Model deployment, orchestration, and serving on Kubernetes.
4. Pachyderm #
- Features: Pachyderm is focused on data versioning and pipeline automation. It uses Kubernetes for scaling and supports data lineage tracking.
- Use Cases: Data pipelines, version control, reproducibility.
5. Valohai #
- Features: Valohai provides a platform for managing machine learning experiments and pipelines, focusing on scalability and reproducibility. It is cloud-agnostic and integrates with various ML tools.
- Use Cases: Large-scale experiment management, pipeline automation.
6. ClearML #
- Features: ClearML (formerly Trains) is an open-source MLOps suite for experiment management, data management, and model deployment. It integrates seamlessly with existing workflows.
- Use Cases: Experiment tracking, data management, deployment.
7. SageMaker Studio #
- Features: Amazon SageMaker Studio is an integrated development environment for machine learning that includes tools for experiment management, model training, and deployment.
- Use Cases: End-to-end ML development, deployment, and monitoring.
8. Polyaxon #
- Features: Polyaxon is a platform for reproducible and scalable machine learning and deep learning on Kubernetes. It supports experiment tracking, hyperparameter tuning, and model management.
- Use Cases: Experimentation, hyperparameter tuning, deployment on Kubernetes.
9. Dagster #
- Features: Dagster is an orchestrator for machine learning and data pipelines. It helps manage and monitor complex workflows with a focus on reliability and scalability.
- Use Cases: Workflow orchestration, pipeline management.
10. Airflow (Apache Airflow) #
- Features: Apache Airflow is an open-source tool for orchestrating complex workflows, including machine learning pipelines. It allows you to define, schedule, and monitor workflows programmatically.
- Use Cases: Workflow automation, scheduling, and monitoring.
11. Metaflow #
- Features: Metaflow is a human-centric framework that helps data scientists and engineers build and manage real-life data science projects. It provides an intuitive API for managing data, dependencies, and compute resources, and it integrates seamlessly with the existing ML and AI tools.
- Use Cases: Experiment management, data pipeline orchestration, versioning of code, data, and models, and scaling machine learning workflows.
12. Airflow (Apache Airflow) #
- Features: Apache Airflow is an open-source tool for orchestrating complex workflows, including machine learning pipelines. It allows you to define, schedule, and monitor workflows programmatically using Directed Acyclic Graphs (DAGs). Airflow provides rich integrations with various data sources, task dependencies, and notification systems.
- Use Cases: Workflow automation, scheduling, and monitoring, especially in data engineering, ETL processes, and machine learning model orchestration.
13. ZenML #
- Features: ZenML is an extensible, open-source MLOps framework built to create reproducible machine learning pipelines. It abstracts away infrastructure complexity, enabling you to focus on experimentation while ensuring consistent and repeatable deployments. ZenML integrates with various tools and frameworks like TensorFlow, PyTorch, and Kubernetes.
- Use Cases: Building reproducible ML pipelines, infrastructure abstraction, and seamless integration with existing ML tools.
14. MLReef #
- Features: MLReef is an open-source MLOps platform that simplifies the entire machine learning lifecycle. It supports collaborative development, data versioning, experiment tracking, and model deployment. MLReef also emphasizes collaboration, allowing teams to work together on datasets, models, and experiments.
- Use Cases: Collaborative machine learning, data versioning, experiment tracking, model deployment, and managing end-to-end ML projects.
15. Seldon #
- Features: Seldon is an open-source platform designed for deploying, scaling, and managing machine learning models in Kubernetes environments. It supports various frameworks and languages, offering features like canary deployments, A/B testing, and monitoring. Seldon also provides explainability and drift detection capabilities.
- Use Cases: Scalable model deployment in Kubernetes, model monitoring, canary deployments, A/B testing, and explainability.
16. Argo #
- Features: Argo is an open-source workflow engine that orchestrates parallel jobs on Kubernetes. It supports complex workflows, including those involved in machine learning pipelines, by defining them as DAGs. Argo integrates well with Kubernetes, making it suitable for CI/CD pipelines, batch processing, and data processing tasks.
- Use Cases: CI/CD pipelines, workflow orchestration in Kubernetes, batch processing, and machine learning pipeline orchestration.
17. MLflow #
- Features: MLflow is an open-source platform that supports the entire machine learning lifecycle, including experiment tracking, model management, and deployment. It offers four key components: Tracking, Projects, Models, and Registry, which allow users to manage experiments, package code, manage models, and streamline model deployment workflows. It integrates well with various ML libraries and cloud services.
- Use Cases: Experiment tracking, model versioning, reproducibility, production deployment, and model registry.
These tools vary in their focus, with some offering comprehensive MLOps solutions and others focusing on specific aspects such as data versioning, deployment, or pipeline orchestration. The choice of tool depends on your specific needs, infrastructure, and the scale of your ML operations.
What are popular CI/CD tool? #
- Jenkins is a free and open-source CI/CD tool that is widely used by developers. It is a powerful tool that can be customized to meet the needs of any project.
- Travis CI is a hosted CI/CD service that is integrated with GitHub. It is a popular choice for open source projects.
- CircleCI is another hosted CI/CD service that offers a variety of features and pricing options. It is a good choice for projects that need a high level of automation.
- TeamCity is a commercial CI/CD tool that is offered by JetBrains. It is a powerful tool that can be customized to meet the needs of any project.
- Bamboo is a commercial CI/CD tool that is offered by Atlassian. It is a good choice for teams that use Atlassian products, such as Jira and Confluence.
- Github Actions a general-purpose automation framework integrated deeply with GitHub’s ecosystem.
- Wrecker
- GitLab
- Buddy
- Codeship
- GoCD
- Wercker
- Semaphore
- Nevercode
- Spinnaker
- Buildbot
These tools offer a variety of features and capabilities, so it is important to choose one that is right for your specific needs. Some factors to consider when choosing a CI/CD tool include:
- The size and complexity of your project
- The type of development environment you use
- Your budget
- The level of automation you need
Once you have chosen a CI/CD tool, you can start automating your software development process. This will help you to improve the quality of your code, reduce the time it takes to release new features, and make it easier to deploy your applications.
What CI/CD tool is the best for small project? #
If I am developing project in python, my team size is 10 developer. I have 3 testers for functional testing. I don’t want to spend extra on CI/DI tools. My project’s sprint duration is 2 week then which CI/CD tool is the best?
Based on your requirements, I would recommend using Jenkins. Jenkins is a free and open-source CI/CD tool that is widely used by developers. It is a powerful tool that can be customized to meet the needs of any project. Jenkins is also easy to set up and use, making it a good choice for teams that are new to CI/CD.
Here are some of the benefits of using Jenkins for your Python project:
- Free and open-source: Jenkins is a free and open-source tool, so you can use it without having to spend any money.
- Powerful: Jenkins is a powerful tool that can be customized to meet the needs of any project.
- Easy to set up and use: Jenkins is easy to set up and use, making it a good choice for teams that are new to CI/CD.
- Widely used: Jenkins is widely used by developers, so there is a large community of users and documentation available.

Comments: