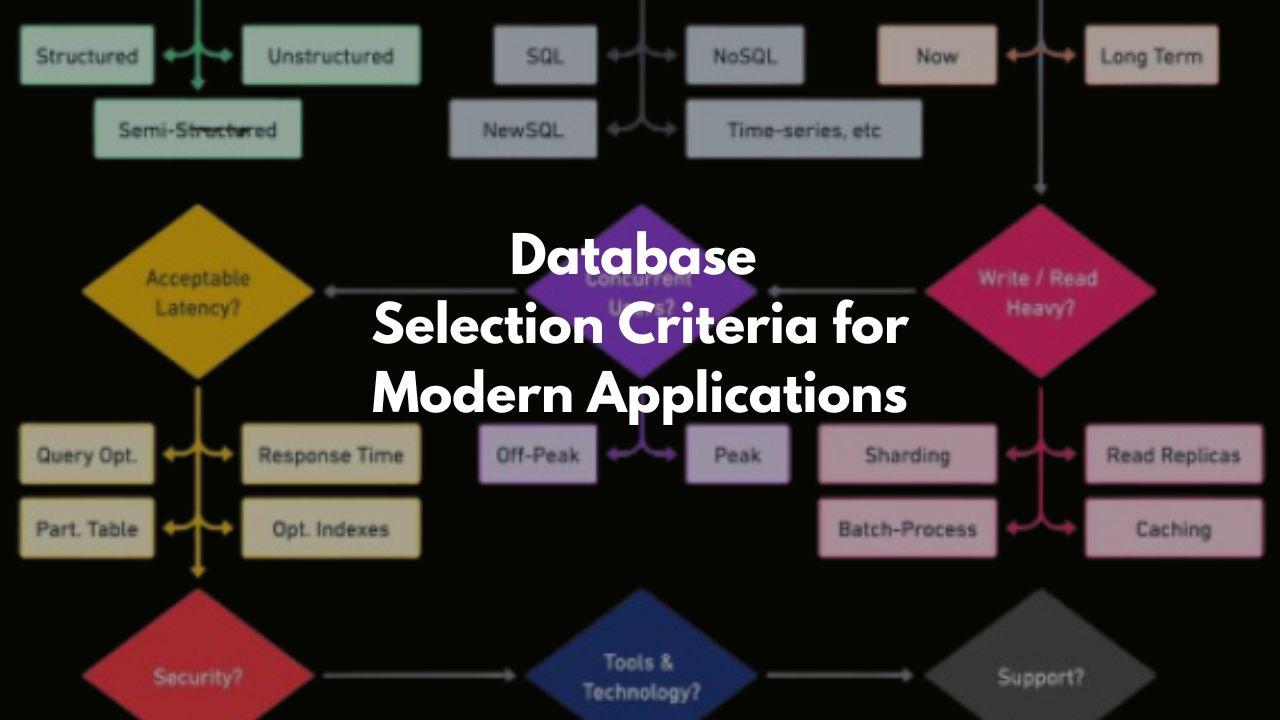
Essential Database Selection Criteria for Modern Applications #
Is this article for me? #
If you are looking answer for these questions then “Yes”.
- What parameters should you consider to choose a database for your project?
- What are different data formats for bigdata?
- What is the difference between OCR and Parquet data formats?
- What is CAP Theorem?
- What is the difference between Sharding and Partitioning
What parameters should you consider to choose a database for your project? #
When you are developing an application which need to store the data or you need to pull data from some format for your project work that time you need to take care of many parameters. Sometimes it looks there is an ovbious choice to go for a certain type of database for some specific work but most of the time it is challenging. What are those aspects of a database which you need to take care of?
Here are more parameters to consider when selecting a database:
- Scalability: Ability to handle increasing data load, both vertically (adding resources to a single node) and horizontally (adding more nodes).
- Read/Write Performance: How efficiently the database handles read and write operations, especially in high-traffic environments.
- Replication and Backup: Support for data replication across multiple locations or servers to ensure data availability and fault tolerance. If you need to manage this manually then it can be painful.
- Consistency: How strictly the database maintains consistency across replicas (e.g., eventual consistency in NoSQL vs. strong consistency in relational databases).
- Latency: The delay between request and response, critical for near to real-time applications.
- Availability: Ensuring the database is always available, even in the face of network partitions or server failures (related to the CAP theorem).
- Indexing: Support for creating indexes to optimize query performance, especially for large datasets.
- Sharding: Ability to partition data across multiple servers for better load distribution and handling large datasets.
- Partitioning: Support for dividing a table or index into smaller, more manageable pieces for performance and maintenance.
- Security Features: Encryption, user authentication, access control, and role-based security to ensure data protection.
- Caching Mechanisms: Built-in support for caching frequently accessed data to improve query performance.
- Data Redundancy: Mechanisms for duplicating critical data to avoid loss or downtime in case of failures.
- Data Integrity Constraints: Support for enforcing integrity rules (like primary key, foreign key constraints) to ensure data correctness. If you need to ensure this integrity from the front-end application it becomes inefficient, insecure and unsafe. Someone either from front-end or backend can do the something wrong intentionally or unintentionally.
- Data Retention and Purging: Policies for retaining and purging data over time to manage storage and regulatory requirements. That policy support is available within database engine or you need to manually take care of this?
- Defined Schema: Determines whether the database enforces a fixed schema for data structure (e.g., relational databases).
- Alternation in Schema: Flexibility to modify the schema without disrupting the database operations (e.g., NoSQL databases allow this easily).
- Compression: The ability of the database to reduce storage size through compression techniques, optimizing space usage.
- Querying: The efficiency and flexibility of the database’s query language for retrieving data (e.g., SQL, NoSQL query models).
- Distributed vs Central Processing and Storage: Whether the database is designed for distributed storage and processing across multiple nodes or centralized on a single server.
- Human-Readable Format: Support for formats like JSON or CSV that make data easily understandable and editable by humans.
- Volume Handling: The capacity of the database to efficiently manage large volumes of data at scale.
- Concurrent Processing: How well the database handles multiple simultaneous read/write operations without conflict or delay.
- ACID Transaction Support: Ensures reliable transactions with atomicity, consistency, isolation, and durability guarantees.
- Audit Trail or Transaction Log: Maintains a log of all database transactions and changes for traceability and recovery.
- Transaction Isolation Levels: Levels of isolation between concurrent transactions (e.g., read uncommitted transactions, avoiding repeatable read).
- Cross-Platform Support: Whether the database can be deployed across different operating systems and environments.
- Eventual vs. Strong Consistency: In distributed databases, how the system handles consistency between nodes.
- Integration with Analytics Tools: Native support or integration with analytical tools and libraries (e.g., integration with Hadoop, Spark, or ML libraries). If this support is not available then to use the data for example, for analytics or machine learning purpose, we need to export this into other formats.
- Fault Tolerance and Recovery: Mechanisms for detecting and recovering from faults without data loss.
- Temporal Data Support: Native support for time-series data, versioning, and time-bound queries. This ensures consistency, performance, compression etc. Otherwise we need to take care of time, date functions for the transactions.
- Data Types Supported: Whether the database supports complex data types like JSON, geospatial data, arrays, or nested structures. Putting some json or map or array data in some string variable of the dataset is an inefficient solutions. We need to look for a database which can handle these complex data strictures.
- Migration Support: Tools or features that make migrating data between different database systems easier. Or tomorrow if you want to migrate into other databases then what will happen?
- Concurrency Control Mechanisms: Techniques like optimistic/pessimistic locking to ensure proper handling of concurrent transactions.
- Tooling and Ecosystem: Availability of administrative tools, monitoring systems, and third-party ecosystem support for the database.
What are different data formats for bigdata? #
Big data is stored and processed in various formats, depending on the use case, storage mechanism, and processing requirements. Here are some of the most commonly used data formats in the big data ecosystem:
1. Text-Based Formats #
- CSV (Comma-Separated Values):
- Plain text format with rows of data where columns are separated by commas.
- Simple and widely used for structured data.
- Easy to read and write but lacks support for complex data types.
- JSON (JavaScript Object Notation):
- Semi-structured format.
- Hierarchical structure with key-value pairs.
- Great for web-based applications but can be verbose and inefficient for large datasets.
- XML (eXtensible Markup Language):
- A flexible, structured format used to store hierarchical data.
- Self-describing tags make it readable, but it’s verbose and complex.
2. Row-Based Formats #
- Avro:
- A row-based format developed within the Hadoop ecosystem.
- Supports schema evolution, meaning it allows schema changes over time.
- Highly efficient for both serialization and deserialization.
- Great for streaming data, with compact and fast encoding.
3. Columnar Formats #
- Parquet:
- Columnar storage format that is highly efficient for analytical queries.
- Great for read-heavy workloads, especially when only a subset of columns is required.
- Used in tools like Hadoop, Spark, and AWS Redshift.
- ORC (Optimized Row Columnar):
- Also a columnar format optimized for big data, especially with Hive and Hadoop.
- Offers efficient compression and fast query processing by supporting predicate pushdown.
4. Binary Formats #
- Sequence File:
- A binary format for Hadoop’s MapReduce framework.
- Stores key-value pairs in binary format, making it efficient for read and write.
- Lacks schema support and is largely replaced by Avro and Parquet.
- Protocol Buffers (Protobuf):
- A compact binary format used to serialize structured data.
- Developed by Google, it provides a balance between efficiency and flexibility.
- Supports schema evolution like Avro.
5. NoSQL-Specific Formats #
- BSON (Binary JSON):
- A binary form of JSON, used primarily by MongoDB.
- Allows for rich data types but is more compact and efficient than plain JSON.
- HBase KeyValue Format:
- Specific to HBase, a column-oriented NoSQL database.
- Stores data in the form of key-value pairs optimized for wide-column data models.
6. Compressed Formats #
- Gzip:
- Commonly used to compress text-based formats like CSV, JSON, and XML.
- Reduces storage space but may add overhead to processing due to decompression.
- Snappy:
- A fast, block-oriented compression library developed by Google.
- Used by Parquet and Avro for compressing data without compromising speed.
7. Log Formats #
- Syslog:
- Standard log format used for system logs and logging services.
- Typically plain text but can be structured with key-value pairs.
- Logstash JSON:
- JSON-based format used by the ELK (Elasticsearch, Logstash, Kibana) stack for ingesting and storing log data.
8. Other Formats #
- Delta Lake:
- Provides ACID transactions on top of existing data formats like Parquet.
- Often used in data lakes with tools like Apache Spark.
- Apache Iceberg:
- A table format for huge analytic datasets, allowing for versioning, schema evolution, and optimized access patterns.
These formats serve different purposes, depending on the use case, data size, and processing tools. Columnar formats (like Parquet and ORC) are typically more efficient for analytics, while row-based formats (like Avro) work better for streaming and write-heavy applications.
What is the difference between OCR and Parquet data formats? #
Parquet and ORC (Optimized Row Columnar) are both columnar data formats commonly used in big data environments like Hadoop and Spark, but they have some differences:
1. Parquet: #
- Developed by: Cloudera and Twitter.
- Primary Use Case: Optimized for read-heavy workloads, particularly in analytical queries where only a subset of columns is required.
- Compression: Parquet offers flexible compression codecs like Snappy, Gzip, and LZO.
- Compatibility: Widely supported across various ecosystems like Apache Spark, Hadoop, Hive, and AWS.
- Advantages: Best for use cases with complex nested data structures (like arrays, structs) and when you need to access specific columns frequently.
2. ORC (Optimized Row Columnar): #
- Developed by: Hortonworks for the Apache Hive project.
- Primary Use Case: Optimized for heavy read/write operations, especially in Hive-based systems.
- Compression: ORC provides advanced compression features (like lightweight compression for faster processing) and better compression ratios than Parquet.
- Compatibility: Highly optimized for Hive but can also work with other tools like Spark.
- Advantages: Provides better performance for heavy read/write use cases, better support for predicate pushdown, and efficient storage.
In Brief: #
- Parquet is widely compatible and excels at reading specific columns from large datasets, while ORC is optimized for Hive and handles read/write workloads with better compression and query performance for large, structured datasets.
What is CAP Theorem? #
The CAP Theorem, proposed by Eric Brewer, is a fundamental principle that applies to distributed databases. It states that in a distributed system, it is impossible to simultaneously guarantee all three of the following properties:
- Consistency (C): Every read receives the most recent write or an error. This means all nodes in the system have the same data at any given time, ensuring data integrity.
- Availability (A): Every request (read or write) receives a non-error response, even if the response is not the most recent one. This ensures that the system is always responsive and up.
- Partition Tolerance (P): The system continues to operate, even if network partitions (communication failures between some nodes) occur. In other words, the system can tolerate faults that separate parts of the network.
CAP Theorem in Practice: #
According to the CAP theorem, a distributed database can only guarantee two out of the three properties at the same time:
- CP (Consistency and Partition Tolerance): The system will ensure data consistency even if part of the network is unavailable, but it may sacrifice availability. Example: HBase.
- AP (Availability and Partition Tolerance): The system will remain available and tolerate network partitions, but data consistency may not be guaranteed across all nodes. Example: Cassandra, DynamoDB.
- CA (Consistency and Availability): The system is always consistent and available but cannot handle network partitions. This is more theoretical, as network failures are inevitable in distributed systems.
What is the difference between Sharding and Partitioning #
Sharding and Partitioning both involve dividing data into smaller, more manageable pieces, but they are used in different contexts and have distinct characteristics:
- Sharding: Sharding is a form of horizontal partitioning used to distribute data across multiple servers or nodes. Each shard holds a subset of the total data, and the shards work together to form the complete dataset. Sharding is typically used in distributed databases to handle large volumes of data and scale out horizontally across multiple machines. Each shard is essentially a separate database. The data is divided based on some criteria (e.g., customer ID, geographic location), and each shard operates independently. MongoDB, Cassandra, and Elasticsearch use sharding to distribute data across multiple nodes for better scalability and performance.
- Benefits:
- Increased scalability (horizontal scaling).
- Higher performance by distributing the load.
- Fault tolerance, as each shard can be isolated.
- Challenges:
- More complex to manage.
- Requires consistent hashing or logic to route queries to the appropriate shard.
- Partitioning: Partitioning refers to splitting data within a single database into smaller, more manageable chunks, typically based on some key (e.g., date, region). This is usually done for performance optimization. Partitioning is often used in large relational databases (e.g., Oracle, PostgreSQL) to improve query performance and manage data more efficiently. The data is split into partitions based on a well-defined rule but remains within the same database system.
- Types of Partitioning:
- Horizontal Partitioning: Divides rows of a table into multiple smaller tables (similar to sharding but within the same database).
- Vertical Partitioning: Divides columns of a table into separate tables, useful when frequently accessed data differs.
- Range Partitioning: Data is partitioned based on ranges of a key (e.g., date ranges).
- List Partitioning: Based on specific values (e.g., different regions or countries).
- Hash Partitioning: Data is distributed based on a hash function, ensuring even distribution.
- Benefits:
- Improved query performance.
- Simplified maintenance (e.g., purging old partitions).
- Easier backup and recovery operations.
- Challenges:
- More complex query planning.
- Potential skew if the partitioning logic is not evenly distributed.
Hashtags #
#DatabaseSelection #BigData #DistributedSystems #CAPTheorem #Sharding #Partitioning #ACIDTransactions #DataStorage #DataManagement #TechInsights

Comments: